对存在中心节点的分布式文件系统的总结与思考
0. 前言
本文是在学习GFS(The Google File System,谷歌文件系统)后对存在中心节点的分布式文件系统的一些宏观的总结与思考。本文并没有太多关注GFS的细节实现,而是侧重在GFS的基础上进行归纳和进一步探究。
1. 为什么需要分布式文件系统?
关于这个问题,百度百科是这么说的
计算机通过文件系统管理、存储数据,而信息爆炸时代中人们可以获取的数据成指数倍的增长,单纯通过增加硬盘个数来扩展计算机文件系统的存储容量的方式,在容量大小、容量增长速度、数据备份、数据安全等方面的表现都差强人意。分布式文件系统可以有效解决数据的存储和管理难题.....
更深层次而言,纵观人类软件系统的发展史,业务的爆炸不断驱动着技术飞速发展。随着接入网络的人数越来越多,软件系统也需要不断升级以能够满足海量用户的并发请求。而软件系统的升级过程,就是不断挑战性能瓶颈的过程。从这个角度出发,用户的增多必然会导致单机无法容纳需要持久化的数据,即使采用增加硬盘个数的方式将单机不断扩大,在达到一定规模后,查找有关数据的操作会变得非常缓慢,掣肘整体软件性能的提升。为了解决这些问题,分布式文件系统几乎是必经之路,也是唯一选择。
2. 分布式文件系统理想的实现效果?
最终目标只有一句话:用户使用分布式文件系统,感觉就像在使用单机文件系统一样。
而限制这一最终目标达成的最主要因素,就在于网络和机器都不是百分百的可靠。系统运行期间网络的一点点波动、时延,或者机器的一点点故障,都有可能造成用户无法看到或看到不符合预期的结果。
3. 分布式文件系统的要求?
- 大容量。这点是分布式文件系统的基础要求,也是固有属性。如果大容量都无法满足,那还不如单机的文件系统。
- 支持并发访问。支持的并发数量是衡量分布式文件系统性能的重要指标之一。
- 持久化。这也是基础要求,数据不能持久化的分布式文件系统是没有太大意义的。
- 高可用。分布式文件系统会存在很多服务器,难免会出现某个服务器宕机的情况,这种情况下仍需要保证文件系统的正常运转。
- 一致性。衔接上一条高可用,冗余备份是实现高可用最常见的方式,而一致性是冗余备份无论如何也绕不开的关键问题。
- 低时延。没有用户愿意在发出一个请求后经历漫长的等待,时延也是衡量分布式文件系统性能的重要指标之一。不过关于这一点,不同的分布式文件系统有不同的要求,比如GFS就没有过于追求某一次操作的低时延,而是更注重持续、稳定的带宽。
- 可拓展(具有伸缩性)。系统都是随着业务规模的扩大不断升级,当业务需求对系统提出新的要求后,可拓展性就显得尤为重要。
4. 分布式文件系统的系统模型
本文的系统模式是存在中心节点的分布式文件系统模型。
谷歌文件系统(The Google File System)的系统模型就是非常经典的下图:

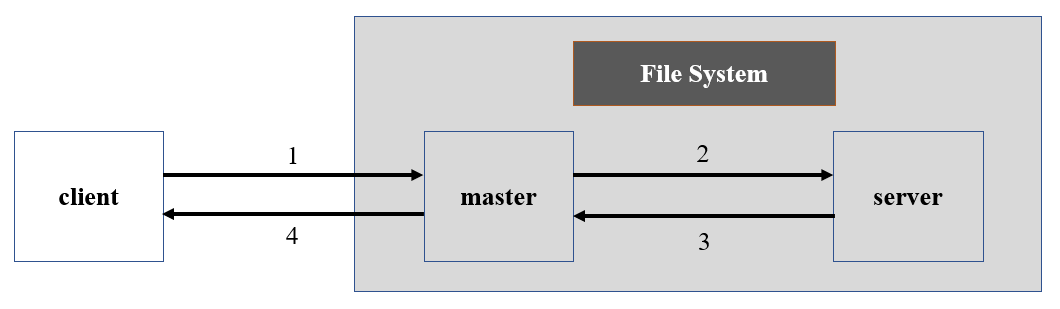
我将该系统提取成为了一个较为通用的抽象模型:

在该模型中,分布式文件系统主要有master部分和server部分组成。master部分需要承载用户的访问请求并对所需资源进行定位,出于负载均衡方面的考虑一般不存储文件;server部分是真正用来存放文件数据的部分。不同的分布式文件系统对master部分和server部分的可能会有不同的具体实现,但功能大体相似。
以该抽象模型为例,用户想在系统中查询文件的工作流程大致如下:
client向系统的master发送查询请求,请求中包含需要查询的文件的信息。
master获取client需要所需内容在server中的位置坐标,并返回client。
client根据查询内容的位置坐标找到相应的server节点,并发送查询请求。
server将查询的内容返回给client,查询过程完毕。
上述流程以查询为例,增加、修改、删除的操作也类似。
需要注意的是,分布式文件系统也可以采用如下模型:
但该模型中,master还需要承担向server发送文件请求并接受文件内容的任务,在并发场景下I/O负担会加重到难以想象,master极易成为系统的性能瓶颈,因此并不可取。
5.如何满足分布式文件系统的要求?
这部分将参照上文的第三部分,以GFS系统为参考,但不仅限于GFS系统,逐条进行解决方案说明与分析:
大容量。系统中的server部分存在多个存储节点满足系统大容量的需求,对应GFS中存在多个chunkserver。存储节点越多,系统的容量越大,但也会相应的提高系统的运营成本,给系统性能带来更大的挑战。
支持并发访问。系统对并发的支持主要体现在两个方面:第一.master部分可以支持多个client并发查询文件所在的server坐标。第二.server可以支持多个client并发的操作数据。当然,并不是所有的分布式文件系统都需要同时满足这两种并发,例如,master完全可以采用类似生产者-消费者的方式,client的查询请求加入master队列,然后master逐条取出并处理。
持久化。master和server都会将自身的数据保存到磁盘,server自然不必多说,会持久化存储的文件数据,master部分需要持久化的东西较为复杂,不同的分布式文件系统持久化的内容也存在差异,我理解对于大多数系统而言,master至少应该持久化两部分内容:1)文件与server的信息,如两者的命名空间、映射关系等 2)server中各个节点的最新版本id,节点版本id存在的必要是为了满足一致性。
值得注意的是,由于GFS采用了给节点头分配租约(lease)的方式,因此并不需要持久化server当前的主节点(primary)。另外,GFS的持久化方式是日志(log)+checkpoint,checkpoint是为了防止日志随着时间的增长膨胀得太大。这种log+checkpoint的方式非常不错,也是redis等常用软件中采用的方式。
高可用。最常见的方式就是冗余备份了,在GFS系统中高可用主要体现在两个方面:
1)master的高可用。master的操作日志、存档等数据会被复制到多台机器,master故障时,监控设备会在冗余机器上启动新的master进程,并采用更新DNS的方式引导client访问新的master,保证系统持续可用。另外,GFS还提供了阴影master,阴影master能在master故障时提供只读服务,但是阴影master的数据通常会落后1秒左右。
2)server的高可用。每份数据默认有3个chunkserver进行备份,当然,3个只是默认值,会根据不同文件的访问热度进行灵活调整,避免3个chunkserver无法应对热点数据的请求而成为系统瓶颈。在冗余备份时,需要考虑不同的server节点放置在不同的位置,如GFS会将同一文件不同的备份机放到不同的机架上,避免整个机架故障造成系统瘫痪,如今,大型系统需要考虑备份不仅放在不同的机架,甚至要越远越好,即"异地容灾备份"。
一致性。多备份解决了高可用问题,但同时会引入一致性问题,不同的备份所处地理距离越远,安全性越高,但一致性越困难。一致性产生的最根本原因就是网络的不可靠性,如果存在绝对可靠的网络,那也不会存在一致性的难题,虽然随着如今网络的发展,网络出现不可靠的概率越来越低,但在设计分布式系统时,仍然需要考虑网络每时每刻都存在不可靠的可能性,注意,一定要假设每时每刻都可能发生网络故障,这对系统的一致性是非常巨大的挑战。
在GFS系统中,大部分文件发生变化都是因为执行了追加(append)操作,而通常不会发生内容的覆盖。GFS保证append操作一致性采用的松弛一致性模型:append操作会发送给多个备份中实时的primary节点,由primary节点指定执行顺序,并通知其他节点。在其他节点全部执行成功后,primary节点会告诉client执行成功了,否则只要有一个节点执行失败,primary就会告诉client失败了,需要client重新发起操作请求。这个过程中,如果执行失败了,该过程并不会删除已经append成功的节点中的文件信息,这显然会造成不必要的空间浪费,这也是我认为GFS可以改进的点之一,比如采用两阶段提交或三阶段提交的方法。另外,如果GFS同时存在读和写,那么读的线程有可能会读到没有写完整的数据,这也是GFS做的不够严谨的地方之一,这一问题可以采用写时复制、读的过程中检查是否读到了正在写入的位置等方式进行改进。
低时延。缓存是减少时延非常有效的手段,但是在缓存的同时需要考虑缓存与磁盘数据的一致性问题。GFS的客户端会缓存一些chunk句柄或对应的chunkserver的位置(这部分信息通常不会变化,因此不会存在复杂的一致性问题),但并不会缓存文件数据,因为该系统的业务场景下文件重用率不高,缓存文件内容的收益较小。在chunkserver中,chunk被存储为本地文件,此时Linux会提供操作系统层面的缓存,GFS没有进行额外的缓存处理。
另外,GFS还采用了特殊的方式缩短查询请求的时延:在查询的时候,不是必须经过primary节点,而是根据距离、负载等因素选择能够最快响应的server节点查询。
可拓展(具有伸缩性)。系统的可拓展性主要考虑两个方面:
1)master的可拓展性。master的可拓展方式主要有将单机master拓展为多机master,具体实现可采用主从机制。但是在GFS系统中,并没有对master进行拓展。这主要是因为,GFS以较大的数据块存储文件数据(每个chunkserver保存64M),这就能够尽量减少master保存的server信息,并减少client与master交互的次数,同时,client在查询有关文件信息的时候,很有可能会在同一次查询中额外询问一些后续的chunk信息,master有时也会主动告知client一些后续额外chunk信息,client同样会缓存这些信息,这在业务主要是顺序读的场景中,几乎不需要增加额外的成本就非常有效的减少了client与master交互的频次,减少了master的负担,如果采用这些方法就能够满足GFS的业务需求,那自然不必画蛇添足去增加多机master。
但是如果考虑更为长远和大规模的场景,随着server的增加,单机master必然会成为系统的瓶颈,系统的升级就是不断与瓶颈做斗争,因此,在一定业务规模下,master的拓展也必须在软件设计之初就加以考虑。
2)server的可拓展性。server的可拓展性指的是随着系统存储文件数量的不断增大,server节点不够用时,需要补充新的server节点,此时需要新节点向master进行注册,master便可以给新节点分配数据。master在给新节点分配数据时,可以借助新节点进一步实现系统的负载均衡,但也应该注意,不要为了缓解负荷较重节点的压力一下子将过多的热点数据分配给新节点,这会造成新节点短期内负载突然增大。
6. 总结与后记
本文是在对GFS学习后,阅读了一些相关文章,对存在中心节点的分布式文件系统进行的归纳,从分布式文件系统存在的意义、终极目标说起,依据自己抽象出来的分布式文件系统通用模型分析了如何满足分布式文件系统应该满足的要求。
本文很多内容都是以GFS的实现方式为例,对GFS的优缺点进行了简单的探讨。文中提到的GFS可以改进的点,只是针对我认为较为通用的场景,并没有过多的考虑GFS的业务场景,因此可能在特定业务场景下并不成立。
由于本人水平有限,难免会存在错误纰漏,欢迎大家与我交流,欢迎批评指正!谢谢!
7. 参考文献
- Ghemawat S , Gobioff H , Leung S T . The Google file system[J]. Acm Sigops Operating Systems Review, 2003, 37(5):29-43.
- 分布式文件系统设计,该从哪些方面考虑?
- 经典论文翻译导读之《Google File System》
没有评论:
发表评论