欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
Flink处理函数实战系列链接
- 深入了解ProcessFunction的状态操作(Flink-1.10);
- ProcessFunction;
- KeyedProcessFunction类;
- ProcessAllWindowFunction(窗口处理);
- CoProcessFunction(双流处理);
本篇概览
- 本文是《Flink处理函数实战》系列的第五篇,学习内容是如何同时处理两个数据源的数据;
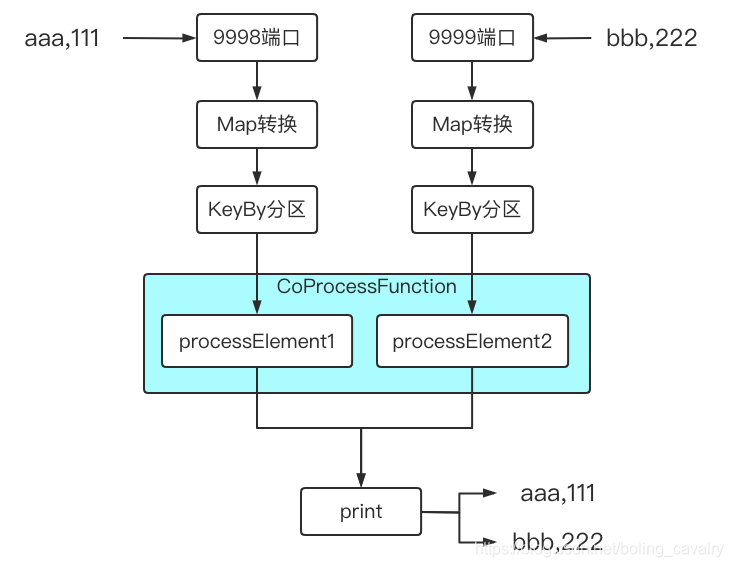
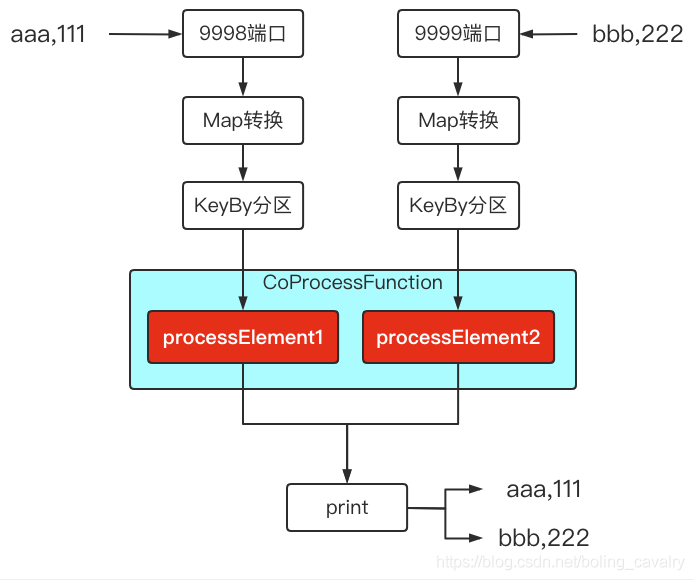
- 试想在面对两个输入流时,如果这两个流的数据之间有业务关系,该如何编码实现呢,例如下图中的操作,同时监听9998和9999端口,将收到的输出分别处理后,再由同一个sink处理(打印):
- Flink支持的方式是扩展CoProcessFunction来处理,为了更清楚认识,我们把KeyedProcessFunction和CoProcessFunction的类图摆在一起看,如下所示:
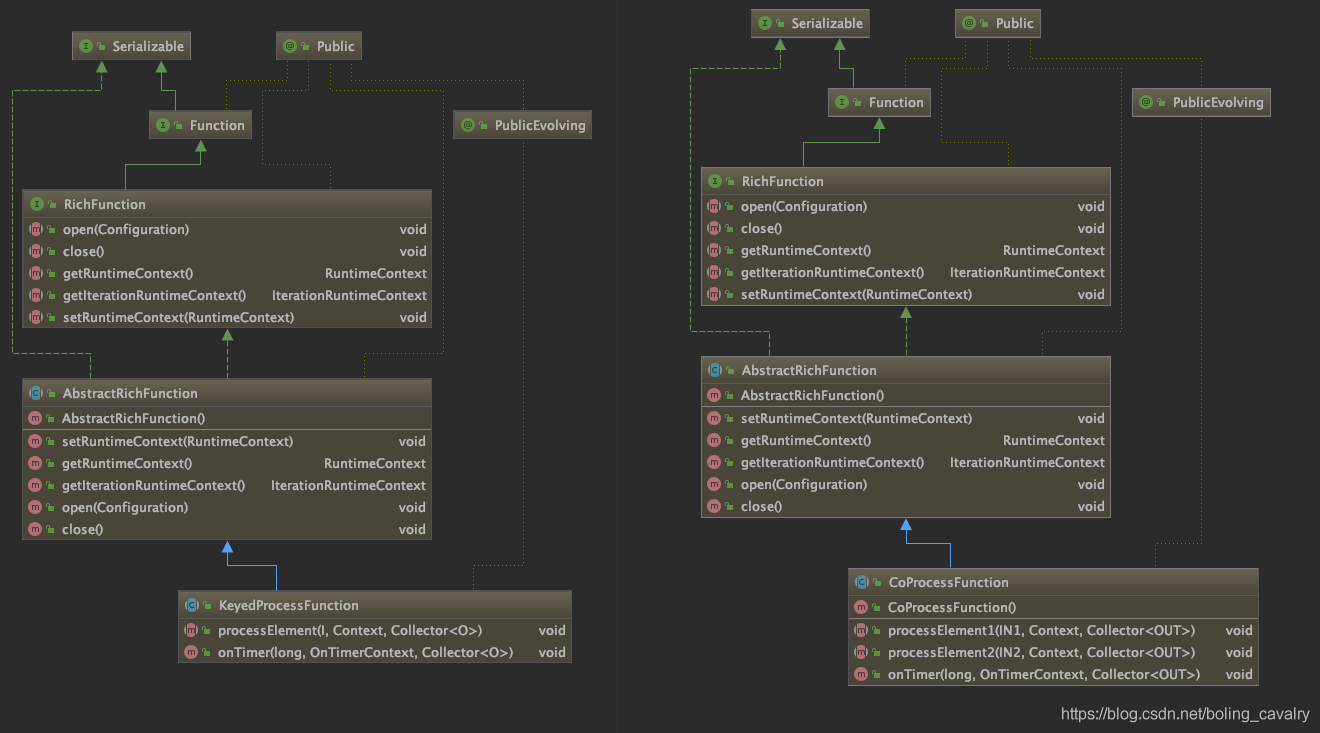
- 从上图可见,CoProcessFunction和KeyedProcessFunction的继承关系一样,另外CoProcessFunction自身也很简单,在processElement1和processElement2中分别处理两个上游流入的数据即可,并且也支持定时器设置;
编码实战
接下来咱们开发一个应用来体验CoProcessFunction,功能非常简单,描述如下:
- 建两个数据源,数据分别来自本地9998和9999端口;
- 每个端口收到类似aaa,123这样的数据,转成Tuple2实例,f0是aaa,f1是123;
- 在CoProcessFunction的实现类中,对每个数据源的数据都打日志,然后全部传到下游算子;
- 下游操作是打印,因此9998和9999端口收到的所有数据都会在控制台打印出来;
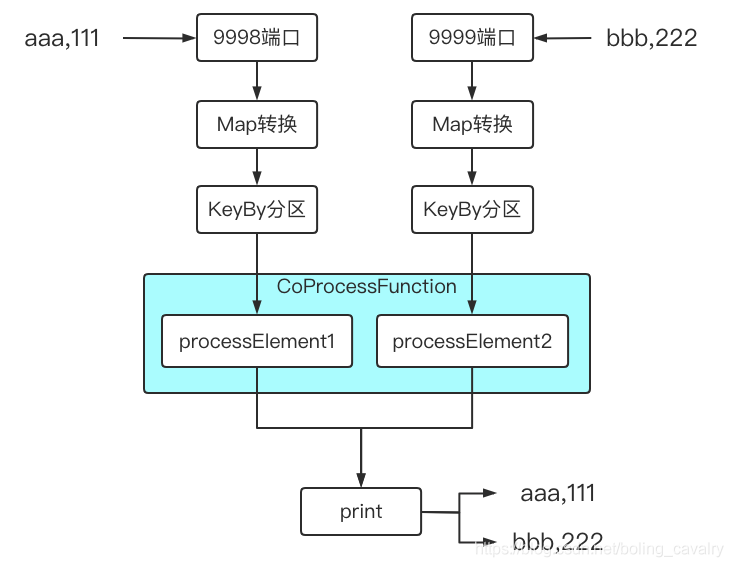
- 整个demo的功能如下图所示:
- 接下来编码实现上述功能;
源码下载
如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
这个git项目中有多个文件夹,本章的应用在flinkstudy文件夹下,如下图红框所示:
Map算子
- 做一个map算子,用来将字符串aaa,123转成Tuple2实例,f0是aaa,f1是123;
- 算子名为WordCountMap.java:
package com.bolingcavalry.coprocessfunction;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.util.StringUtils;public class WordCountMap implements MapFunction<String, Tuple2<String, Integer>> { @Override public Tuple2<String, Integer> map(String s) throws Exception { if(StringUtils.isNullOrWhitespaceOnly(s)) { System.out.println("invalid line"); return null; } String[] array = s.split(","); if(null==array || array.length<2) { System.out.println("invalid line for array"); return null; } return new Tuple2<>(array[0], Integer.valueOf(array[1])); }}便于扩展的抽象类
- 开发一个抽象类,将前面图中提到的监听端口、map处理、keyby处理、打印都做到这个抽象类中,但是CoProcessFunction的逻辑却不放在这里,而是交给子类来实现,这样如果我们想进一步实践和扩展CoProcessFunction的能力,只要在子类中专注做好CoProcessFunction相关开发即可,如下图,红色部分交给子类实现,其余的都是抽象类完成的:
- 抽象类AbstractCoProcessFunctionExecutor.java,源码如下,稍后会说明几个关键点:
package com.bolingcavalry.coprocessfunction;import org.apache.flink.api.java.tuple.Tuple;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.KeyedStream;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.co.CoProcessFunction;/** * @author will * @email zq2599@gmail.com * @date 2020-11-09 17:33 * @description 串起整个逻辑的执行类,用于体验CoProcessFunction */public abstract class AbstractCoProcessFunctionExecutor { /** * 返回CoProcessFunction的实例,这个方法留给子类实现 * @return */ protected abstract CoProcessFunction< Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple2<String, Integer>> getCoProcessFunctionInstance(); /** * 监听根据指定的端口, * 得到的数据先通过map转为Tuple2实例, * 给元素加入时间戳, * 再按f0字段分区, * 将分区后的KeyedStream返回 * @param port * @return */ protected KeyedStream<Tuple2<String, Integer>, Tuple> buildStreamFromSocket(StreamExecutionEnvironment env, int port) { return env // 监听端口 .socketTextStream("localhost", port) // 得到的字符串"aaa,3"转成Tuple2实例,f0="aaa",f1=3 .map(new WordCountMap()) // 将单词作为key分区 .keyBy(0); } /** * 如果子类有侧输出需要处理,请重写此方法,会在主流程执行完毕后被调用 */ protected void doSideOutput(SingleOutputStreamOperator<Tuple2<String, Integer>> mainDataStream) { } /** * 执行业务的方法 * @throws Exception */ public void execute() throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 并行度1 env.setParallelism(1); // 监听9998端口的输入 KeyedStream<Tuple2<String, Integer>, Tuple> stream1 = buildStreamFromSocket(env, 9998); // 监听9999端口的输入 KeyedStream<Tuple2<String, Integer>, Tuple> stream2 = buildStreamFromSocket(env, 9999); SingleOutputStreamOperator<Tuple2<String, Integer>> mainDataStream = stream1 // 两个流连接 .connect(stream2) // 执行低阶处理函数,具体处理逻辑在子类中实现 .process(getCoProcessFunctionInstance()); // 将低阶处理函数输出的元素全部打印出来 mainDataStream.print(); // 侧输出相关逻辑,子类有侧输出需求时重写此方法 doSideOutput(mainDataStream); // 执行 env.execute("ProcessFunction demo : CoProcessFunction"); }}- 关键点之一:一共有两个数据源,每个源的处理逻辑都封装到buildStreamFromSocket方法中;
- 关键点之二:stream1.connect(stream2)将两个流连接起来;
- 关键点之三:process接收CoProcessFunction实例,合并后的流的处理逻辑就在这里面;
- 关键点之四:getCoProcessFunctionInstance是抽象方法,返回CoProcessFunction实例,交给子类实现,所以CoProcessFunction中做什么事情完全由子类决定;
- 关键点之五:doSideOutput方法中啥也没做,但是在主流程代码的末尾会被调用,如果子类有侧输出(SideOutput)的需求,重写此方法即可,此方法的入参是处理过的数据集,可以从这里取得侧输出;
子类决定CoProcessFunction的功能
- 子类CollectEveryOne.java如下所示,逻辑很简单,将每个源的上游数据直接输出到下游算子:
package com.bolingcavalry.coprocessfunction;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.functions.co.CoProcessFunction;import org.apache.flink.util.Collector;import org.slf4j.Logger;import org.slf4j.LoggerFactory;public class CollectEveryOne extends AbstractCoProcessFunctionExecutor { private static final Logger logger = LoggerFactory.getLogger(CollectEveryOne.class); @Override protected CoProcessFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple2<String, Integer>> getCoProcessFunctionInstance() { return new CoProcessFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple2<String, Integer>>() { @Override public void processElement1(Tuple2<String, Integer> value, Context ctx, Collector<Tuple2<String, Integer>> out) { logger.info("处理1号流的元素:{},", value); out.collect(value); } @Override public void processElement2(Tuple2<String, Integer> value, Context ctx, Collector<Tuple2<String, Integer>> out) { logger.info("处理2号流的元素:{}", value); out.collect(value); } }; } public static void main(String[] args) throws Exception { new CollectEveryOne().execute(); }}- 上述代码中,CoProcessFunction后面的泛型定义很长:<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple2<String, Integer>> ,一共三个Tuple2,分别代表一号数据源输入、二号数据源输入、下游输出的类型;
验证
- 分别开启本机的9998和9999端口,我这里是MacBook,执行nc -l 9998和nc -l 9999
- 启动Flink应用,如果您和我一样是Mac电脑,直接运行CollectEveryOne.main方法即可(如果是windows电脑,我这没试过,不过做成jar在线部署也是可以的);
- 在监听9998和9999端口的控制台分别输入aaa,111和bbb,222
- 以下是flink控制台输出的内容,可见processElement1和processElement1方法的日志代码已经执行,并且print方法作为最下游,将两个数据源的数据都打印出来了,符合预期:
12:45:38,774 INFO CollectEveryOne - 处理1号流的元素:(aaa,111),(aaa,111)12:45:43,816 INFO CollectEveryOne - 处理2号流的元素:(bbb,222)(bbb,222)更多
- 以上就是最基本的CoProcessFunction用法,其实CoProcessFunction的使用远不及此,结合状态,可以processElement1获得更多二号流的元素信息,另外还可以结合定时器来约束两个流协同处理的等待时间,您可以参考前面文章中的状态和定时器来自行尝试;
你不孤单,欣宸原创一路相伴
- Java系列
- Spring系列
- Docker系列
- kubernetes系列
- 数据库+中间件系列
- DevOps系列
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
原文转载:http://www.shaoqun.com/a/492901.html
浩方:https://www.ikjzd.com/w/1046
parser:https://www.ikjzd.com/w/680
let go:https://www.ikjzd.com/w/825
欢迎访问我的GitHubhttps://github.com/zq2599/blog_demos内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;欢迎访问我的GitHub这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demosFlink处理函数实战系列链接深入了解ProcessFun
夸克:夸克
eprice:eprice
Ugmonk是如何把产品卖去60个国家的? (Shopify教程):Ugmonk是如何把产品卖去60个国家的? (Shopify教程)
收藏:发美国FBA海运,整柜和拼箱的收费标准!:收藏:发美国FBA海运,整柜和拼箱的收费标准!
2020年深圳春节加班费怎么算啊?:2020年深圳春节加班费怎么算啊?
没有评论:
发表评论